Best way how to monitor server performance 2022

How to monitor server performance, Monitoring of servers is essential to ensure that your server is running at its best and ensure that there are no interruptions for your company. But, monitoring server performance is a complex and dispersed process. Monitoring everything is a difficult struggle. The server’s information allows you to know the root of the issue. Tools, such as Retrace can make this battle efficient and easy to manage. Let’s find out how to track the server’s performance.
What is Server Monitoring?
Monitoring servers involves keeping track of different metrics to ensure seamless running. Monitoring various metrics can help quickly identify the bottlenecks.
Behind every online service that is critical to business There are usually several servers to be accountable either virtual or physical. A physical server can run several engines, leading to numerous functions for servers. Examples of physical servers include databases servers, application servers, and web servers.
Why Server Monitoring is Important
Server Monitoring is crucial to identify problems with performance prior to them impacting the end-user. Server monitoring also aids in understanding the use of resources on the server. This helps you determine the potential of the server.
Monitoring the server can give you an excellent indicator of the server’s responsiveness and availability, all to ensure no disruption to the service you provide to your clients.
Monitoring metrics can also reveal the existence of a cybersecurity risk. This is especially true for hosting websites in which exposure to the internet could lead to an increase in threat to the web server profile.
How to Monitor Server Performance

Caption Web hosting control panels typically contain monitoring tools that aid in showing the use of various resources.
The secret to the success of a server monitoring plan is to determine the areas that need to be targeted and establish a baseline for performance. The proper interpretation of your server’s performance to alert you and gain value-added information through reporting.
There are tools for monitoring servers that can assist in this regard. They can also assist in monitoring the application or entire infrastructure. The Stackify Retrace is a great instrument to implement a reliable monitor of your server. The Stackify RetraceAPM solution offers you an overview of the stack on your server. The Retrace platform is able to automatically analyse every application that contributes to your IT infrastructure, providing you the capability to keep track of the performance of your applications across a variety of metrics and to take action before minor inconsistencies and errors get out of hand. Retrace can help your team:
- Monitoring of app performance
- App manages functions
- A centrally-located log tool
- A line-by-line overview of your program and the way it fits into the larger overall
- Robust error tracking reports
- A set of monitoring services for servers that are real-time.
- Monitoring of individual users
A comprehensive performance monitoring system similar to Retrace allows you to easily analyze your server’s stack and identify weak points before a bigger, more catastrophic failure happens. It provides a comprehensive overview of the way the server as well as its component applications perform under network load.
Key Areas to Monitor
No matter if your servers run in Windows or Unix the following areas of performance are the ideal base to any monitoring strategy for servers. It is essential to keep track of these performance metrics to identify indicators of bottlenecks in performance.
Server’s Physical Status
This is also true for on-site servers These servers require protection from environmental dangers and damages. Apart from placing server in a safe area it is essential to make sure that you control the temperaturesand the power supply of servers are maintained.
The temperature must not be higher than the level recommended for optimal performance within your server environment. If you notice that the temperature is beginning to increase continuously it could be a sign of that there is a problem with your fan or else. It is important to look into the issue.
It is also important to watch those power supply regulators of your server’s power supply. They should be able to manage and smooth out power fluctuations and power surges. If the main supply fail then your Uninterruptible Power Supply (UPS) can give you time for switching to the backup power source.
Central Processing Unit (CPU) & Memory
If a server’s performance declines it is usually due to the server’s CPU usage as well as RAM resources. If you notice that the CPU utilization for your server abnormally excessive or there is a high memory utilization (less space for memory available) the application’s performance may be affected.
It is helpful to know the most efficient processing processes that use memory and CPU within your server. This is essential for resolving issues with resource consumption swiftly. The metrics that should be considered comprise CPU Process Count as well as CPU Thread Count and CPU Interrupt Time in .
You’ll have to keep track of the use of memory on your server. This is a matter of free memory and the rates pages, which are created to free up physical memory space, and other things. These metrics will aid you in understanding the health of your server in all times.
Server Uptime
Your website needs to be operational and accessible round all hours of the day. The server’s uptime is the time that the system is operational. This measure is helpful in notifying you of the possibility that your system has unintentionally restarted.
If you find a difference between the expected availability timeframe and the uptime number, then the system failed at least one time. Verify that all scheduled tasks that were expected to run at the same time that the system was failing were completed.
Disk Activity
Disk activity refers to the time it takes for the disk drive to respond to requests. There are a variety of key indicators that need to be tracked:
- Disk busy time is how long the disk is operational. If this number is high, it indicates that the demands to connect the disk have been increasing.
- Operations for input and output (I/OPs) is a measure of the amount of work being performed on the drive. This metric is important to identify the load your disk is experiencing.
- Disk read/write measures the time it takes to read or write blocks of data off the disk. A lower number indicates that it is performing well.
- Disk queue length is the amount of time required to process requests in the queue. To get the best performance it is recommended that the disk queue’s length must be as short as possible.
Note to monitor the speed of your disk is vital for tasks that are I/O demanding.
Page File Usage
Unused or inaccessible data is saved within the file page file.Operations that go over the limits of the memory of random access (RAM) space of the operating system (OS) are sent in the form of a page file where they are saved.
If you notice that the use is excessive, it signifies that the paging system of the system isn’t enough to satisfy the needs of your server.
Another crucial measure includes page swapping. If your server is out of memory some disk space is allocated to save data temporarily in order to free more space. We don’t recommend switching pages. In most cases, this means you’ve not provisioned enough memory to manage your server.
Keep in mind that page swapping can be a short-term solution to exhaustion of memory capacity. Since page swapping can reduce the speed of response, it should be avoided.
Context Switches
Context switching is a complex process. It happens whenever the operating system (computer software that runs the core of the OS on a computer) shifts the processor’s resources from one thread or process to another. CPU resources are utilized each when a context switching occurs. Therefore, when a large context switching takes place then more and more CPU resources are consumed.
This can be caused by having multiple processes running at the same time or bugs in applications which increase the frequency of context switching. An abrupt increase in the number of context shifting on the server may be a sign of an issue. So, monitoring the number of context switches is vital to ensure the performance of your server.
Time Synchronization
Systems connected to the same network which share files or exchange information with each other have time-bound actions. What happens if clocks on the system are not properly synchronized? The consequences could be catastrophic.
Inaccurate clocks can cause data to be copied or cause conflicting versions. Even worse, it may result in programs not functioning properly. Be sure to monitor offsets of the system clock against the reference clock.
Handles Usage
The term “handles” refers to resources that an application refers to. Applications that run on the server’s request receive resources utilize them following that they’re returned to OS. Sometimes, because of an error by the program an application forgets to return the handle following usage. This is known as a leaky handle.
Keep in mind that the resources on servers are in short supply. Repetitive leaks of handle could exhaust servers over time which can cause the server’s performance and performance to decline. Be aware of and monitor handle usage throughout the course of time. In the event that the quantity of handles that are open is increasing rapidly or in a consistent manner it could indicate that there is a leakage in the handle.
You’ll have to research and find the root of the problem. You can stop these processes or patch the software .
Process Activity
There may be times when applications create new processes and does not stop already running processes. The multi-tasking and handling of these processes could cause stress on your server.
This means that your server’s performance can be affected drastically.Ensure the applications are properly running and shut down properly. To ensure this you must track and monitor the activities of all processes within your server.
Network Traffic
Monitoring network activity is vital for assessing the performance of your server. Every network interface gives an indication of the network’s activity load. If bandwidth utilization is close to the maximum speed that the connection to the internet is running, it could be a sign of a bottleneck.
Through constant monitoring of the input as well as output (I/O) activities on the network card, it is possible to identify a potential hardware failure or overloading. You can also determine the requirements for the hardware to make sure that the server is running at its best.
TCP Activity
Your apps are connected-oriented. They use the TCP protocol to transport data. HTTP, SQL, SMTP use TCP underneath. In the event that your TCP layer performance decreases then so will the performance of your application.
There are many important indicators that can be used to assist in monitoring TCP:
- The speed of connection between the server and its clients is a good indicator of the server’s workload.
- The number of drops in connection for the servers. If the number is high, it could signal the presence of a problem.
- Retransmissions are a percentage of retransmissions. They occur when the server fails to receive an acknowledgement by the user. After a timeout the server is required to transmit the message again. To ensure optimal TCP performance, make sure that retransmissions are kept to the minimal. Be aware that frequent transmissions could result in an extreme decrease in throughput.
OS Log Files
The most popular method for monitoring the condition that your server has is OS logs, as they include information about crashes, errors as well as other irregularities that can assist you to solve any problem.
While Windows provides System, Security, and Application log files, Unix has system log and cron log files that are stored in the directory /var/log. Monitoring, analysis, and monitoring on a regular basis and monitoring of log events can aid in identifying issues with your server.
Monitoring server performance can be a kind of art form, particularly when the server infrastructure and the surrounding network becomes increasingly complicated and dispersed. The process of determining what’s “problematic” is an increasingly challenging task.
The most important elements for the success of a monitoringstrategy is to determine the primary metrics to be targeted and then baseline the metrics to ensure that the server’s performance can be detected for alerting and gaining benefits from the most important metrics through reports.
What are the metrics that are to be targeted?
It is crucial to focus on the most important indicator of performance (KPIs) which are relevant to the servers’ purpose:
- The General Monitoring of Servers and Hosts CPU Memory, Disk Utilization of the Network and Process
- Database Monitoring: Activity of the Database Behavior of Query, User Activity.
- Messaging: Email Database Response and Server Utilization
- Web Server: Network Bandwidth, Busy and Idle Threads, Throughput
- Application Server: Resource Issues, Transaction Volume
These important performance metrics provide a solid base in monitoring any Windows or Unix server monitoring plan.
| Windows Server Performance Metrics | |
| CPU | |
| Process Count | The number of processes running in the computer. |
| Thread count | There are many threads that are running on the computer. |
| % Interrupt Time | A percentage of processor time is spent getting and repairing hardware interrupts. |
| %Privileged Time | The percentage of time the threads are running code while in privilege mode. |
| % Processor Time | The percentage of time that the processor takes to run an unidle thread. |
| % User Time | Percentage of time that the processor is during the mode of user. |
| Disk | |
| Disk Free % | Disk space free percent. |
| Disk Free Space | Space on disks that is free. |
| Disk Reads/sec | The speed at which read operations are performed within the storage device. |
| Disk Writes/sec | The rate at which write operations occur to the hard disk. |
| Disk Read Bytes/sec | The speed at when bytes are transferred from the disk during read operation. |
| Disk Write Bytes/sec | The speed at when bytes are transferred to disks in write operations. |
| Disk Transfers/sec | The speed of write and read processes on the disk. |
| Memory | |
| Free Memory | The amount of memory available. |
| Page Faults/sec | The number of pages that are faulted every second. This count includes soft faults as well as hard ones (those which require access to disk) as well as soft faults (where the page that is faulted is located in memory.) |
| Page Reads/sec | The speed that the drive was read was used to solve hard page issues. |
| Page Writes/sec | The speed at the speed at which pages are written to disk, thereby freeing space in the physical memory. |
| Pages Output/sec | The speed at when pages are written onto disk, thereby freeing the physical memory. |
| Pool Nonpaged Bytes | The amount of bytes of the nonpaged pool an area of memory in the system (physical memory utilized in the operation system) to store objects which can’t write to disk but be kept in memory for as for as long as the space is available. |
| Pool Paged Bytes | The amount of bytes of the pool that is paged, which is an area of memory in the system (physical memory utilized for operating systems) to store objects which may write to disk even when they are not in use. |
| Network | |
| Output Queue Length | Length of queue for outputs |
| Packets Outbound Errors | The amount of outbound packets which could not be sent due to error. |
| Packets Received Errors | The number of packets which contained errors that prevented them from being delivered to a protocol with a higher layer. |
| Kilobytes Received/sec | The rate at which Kilobytes are received via networks. |
| Kilobytes Sent/sec | The rate at which Kilobytes are transmitted over an interface for networks. |
| Unix Server Performance Metrics | |
| CPU | |
| Process Count | The number of processes running in the computer. |
| Thread count | There are many threads running in the computer. |
| % Interrupt Time | The processor’s time is divided into processing and servicing hardware interrupts. |
| %Privileged Time | Percentage of time that process threads are running code while in the privileged mode. |
| % Processor Time | The amount of time the processor takes to run the non-idle thread. |
| % User Time | The processor’s time is measured in % of the time it spends time in user mode. |
| Disk | |
| Disk Free % | Disk space free percent. |
| Disk Free Space | Disk space that is not occupied. |
| Disk Reads/sec | The speed at which read operations are performed in the disc. |
| Disk Writes/sec | The rate at which write operations occur to the hard disk. |
| Disk Read Bytes/sec | The speed at the speed at which data is transferred from the disk during read operation. |
| Disk Write Bytes/sec | The speed at when bytes are transferred to disks when writing operations are performed. |
| Disk Transfers/sec | The speed of write and read operation on disk. |
| Memory | |
| Total Physical Memory | The total amount of physical memory. |
| Free Memory | Memory free |
| Page Faults/sec | The number of pages that have been faulty per second. This counter is comprised of soft faults as well as hard ones (those which require access to disk) as well as soft faults (where the damaged page is within physical memory.) |
| Page Reads/sec | The speed at the time that it was available in order to fix the hard page errors. |
| Page Writes/sec | The speed at when pages are written onto disk in order to free the physical memory. |
| Pages Output/sec | The speed at when pages are written onto disk, thereby freeing space in the physical memory. |
| Pool Nonpaged Bytes | The amount of bytes of the nonpaged memory pool, an area of memory in the system (physical memory utilized for operating systems) used to hold objects, which can’t write to disk but be kept in memory for as the memory is allocated. |
| Pool Paged Bytes | The amount of bytes of the pool that is paged, which is an area of memory in the system (physical memory utilized for operating systems) used to hold objects. may be recorded to the disk even when they are not in use. |
| Network | |
| Output Queue Length | Length of output queue. |
| Packets Outbound Errors | The amount of outbound packets which could not be sent due to errors. |
| Packets Received Errors | The amount of packets inbound which contained errors that prevented them from being delivered to a protocol with a higher layer. |
| Kilobytes Received/sec | The rate at which Kilobytes are received via the interface of network. |
| Kilobytes Sent/sec | The rate at which Kilobytes are transferred over the interface of networks. |
The proper way to determine a monitoring baseline
After the proper KPI’s have been identified , the following step will be to establish the correct alerting criteria. Although some issues are easily identified by the alerting process based on a static value (i.e. disk space problems) However, other issues are more difficult due to the fluctuation of KPI’s, especially the KPIs that fluctuate based on routine workload patterns.
Baselining is the process of determining “usual” behavior and triggering alarms based upon variations from the norm. The principle behind it is to be alerted to issues in availability and performance that aren’t in line with the norm.
What”suspects” to be “usual” mean understanding the server’s purpose and the way it’s used. For instance, is the server operating from Monday to Friday 9-5 job (i.e. the terminal or file/print server)? Are you referring to an application server for databases that offers services for batch processing that is not available during the hours?
The fundamental characteristics will change according to the manner and time the server is being used. Some servers might encounter “usual” changes in workload according to day-of week, time-of-day or even the week of the month. We must be aware of and be aware of the fluctuations.
There are several methods to determine the baseline. One option is to gather the necessary data using the tools available by the operating system , or through an application. You can then analyse the data to identify suitable baselines. It is important to take the time to analyze your data, and determining the performance of your servers (i.e. the time and place they experience fluctuations of workload) is a vital task and you could observe unobserved behavior.
“Normal” patterns aren’t necessarily desirable, for instance, unwanted batch processing during the middle of the day could actually be normal, but it is certainly not something you want to see. It is extremely valuable being able to understand the performance patterns of crucial servers, hosts, and other applications.
When determining a baseline it is essential that the amount of information collected is sufficient to be statistically reliable. The time frame of collection should encompass several instances of shifts or patterns in work. It is not advisable to be relying on a short time frame and not catch the pattern.
Do not restrict your collection of key performance indicators to working hours, since off-prime resources require constant examination. For example, if , for instance, you run nightly processing, you’ll want to be looking for any variations in the behavior of any kind.
We have an analysis from Longitude which is helping to improve benchmark disk performance using and Exchange Server. It is evident that there is a consistent pattern (10:04 midnight each night) that reveals a disk that has an extremely large queue depth (number of read/write operations queued waiting to access disk) which we’ll wish to consider normal and not a sign of a problem because this happens while the backup process is in progress. The objective is to stay clear of alerts of resource issues that are normal or known.
Also Read:
How to start a fire pit with wood 2022
Best Ways how to start a voip provider business 2022
Best Ways how to manage servers 2022
Best Ways how to remove a credit card from uber 2022
How to sell a structured settlement 2022
Another approach to establish the baseline value to establish baseline values for KPIs is to utilize technology that analyzes data and assists you in determining the most appropriate value to trigger alerts.
We see the Longitude, which provides information on the CPU’s usage by formulating the minimum, maximum average for an set of servers.
Reporting: Benefit from your KPIs
All the data collected must be utilized to analyze server performance, identify trends, detect bottlenecks and assess whether the configuration currently in place is functioning according to expectations.
Basic Reporting:
Reporting is a crucial element of any monitoring plan. It’s always an excellent idea to regularly check the efficiency of your system even if you aren’t convinced there’s been any substantial shifts in the work load. It’s not unusual to experience unintended behavior following a software update or patch, but if you’re not attentive to watching for any changes in the behavior of your server, the performance of your IT system may be compromised.
Being able to access reports, even the most elementary of reports can be highly beneficial in aiding IT solve issues with server performance:
- Find out the causes of problems relating to resource use
- Present IT the infrastructure and availability of applications
- Find issues that require attention.
Capacity Management:
The evaluation of capacity is a continuous procedure since IT implementations are always in a state of change. IT performance is an ever-changing goal due to changes in the application’s activity and the results on an IT infrastructure. Planning and managing capacity can help:
- Find out the resources required to meet the projected workload
- Find out how hardware changes can affect the performance of your application
- Baseline applications as well as IT infrastructure
Compliance:
IT departments are often required to agree to a certain degree of performance and accessibility. Utilizing KPI data to demonstrate the conformance to a promise service level will help you to answer questions such as:
- What proportion of time do we have services offered?
- How well are the services doing?
- What is the source of the downtimes and outages in performance?
Conclusion:
If users are bombarded with numerous alerts, it will eventually reach the point that alerts are not taken seriously and, even more so, not even noticed. In the end, the server monitoring approach will turn to an “Boy Who Cried Wolf” scenario.
Targeted alerting is the process of setting thresholds to ensure that only alerts that can be acted upon are generated. The alerts should be relevant within the their context within the particular software or system. A good procedure is to base the alerts off of a reference point and then consider having the minimum as well as the maximum and average values at hand when assessing alerting requirements for performance-based thresholds.
Additionally, the capability to create and analyze reports quickly show the fact that IT can be proactive, and aware of the issues that may have an impact on the business. Reports also demonstrate the positive effect IT can have on an organisation’s productivity, timely delivery, and quality of service by helpingto:
- Give insight into the performance of your application and server
- Improve performance and decrease the amount of time you are down
- Prove the importance of IT
- Find areas in which IT could make improvements
- Service delivery and compliance with documents
Windows Server is typically installed on servers with heavy usage, which serve as the foundation of numerous IT software and applications. If this is the case for your company, it’s essential to keep track the status Windows Server performance monitoring.
The selection of a tool that acts as an Windows Server performance monitor is crucial choosing the appropriate one can make a huge difference in how difficult or challenging your monitoring process will be.
My suggestion would be SolarWinds(r) Server & Application Monitor (SAM) which is an excellent tool that allows that allows for flexible server monitoring and integration via Orion(r) Platform. Orion(r) Platform with other SolarWinds monitoring software and infrastructure monitoring software.
What Is Windows Server Performance Monitoring?

Windows Server performance monitoring refers to the variety of methods that are involved in monitoring the server’s primary performance metrics in order to ensure optimal performance.
Windows Server includes the basic tools built-in to analyze and troubleshoot which allow you to track four important aspects of performance that include those of the server’s CPU memory, hard disks, memory along with the Network Interface Card (NIC). You can look at various indicators that are related to these components in order to check if the server is performing in the way you expect it to.
Even it appears that the server seems to be functioning well, if you monitor it closely, you may be able to find that the CPU is running at 90 percent capacity. While the server is operating admirably currently however, if there is an increase in demand it’s likely to be overloaded.
Another crucial aspect of performing monitoring is the ability to spot any irregularities in your network or attempts to access the network outside of the norm. For instance, if a malicious criminal is trying to penetrate your system, you could be able detect the attempts (and the impact on performance) by monitoring the performance of the servers.
Windows Server Performance Monitoring Best Practices
I’ll share some of my best suggestions to Windows Server monitoring best practices to help make sure that your Windows Server monitoring approach is effective, precise and valuable for the rest of your network.
Define a Baseline
Begin by looking at what the typical performance looks in your servers. If you do not know what an average day or week appears like, it is very difficult to identify any problems. Additionally, make sure your benchmarks and measurements are taken using an “systems” level analysis, which means you look at the entire system and not only the onemetric or component at an time.
For instance, CPU utilization may be high, but it doesn’t mean that the CPU is the only source of issue: the CPU’s utilization may be elevated due to an issue related to the hard disks or even the memory, which could cause problems with flow-on that affect the CPU. It is important to establish baselines to reflect the normal interaction withcomponents in the overall system and not only specific metrics or components.
Furthermore to that, your baseline should not only be what a typical performance looks at on its own. it must have the best performance. You should make sure you utilize Windows Server’s Windows Server performance monitor to make sure that your system is properly optimized and functioning efficiently (not simply working) before you set your baseline.
Monitor Consistently
It’s also important to ensure that your Windows server monitoring of performance is carried out continuously. If you monitor only sporadically it is easy to overlook issues or fail to notice any performance issues until it’s too late. Monitoring systems must be configured to monitor these key components and their performance metrics (including CPU memory, hard disks, memory as well as networks interface card).
Additionally, you must collect data regarding the timing and use of queues and pages, whether there are any issues with the health of your server components and general user behaviour as well as information on server access.
Although it could appear that business hours are most crucial to track but it’s also beneficial to establish a baseline for off-peak hours. Certain processes are programmed to take place during nighttime hours. If you’re not monitoring the performance of your server during these procedures, you may overlook important problems.
Track Key Metrics
Also, you should be sure to keep track of metrics that are relevant for Windows Server. By monitoring specific performance indicators regularly it’s much easier to identify the time and place where the measurements have changed dramatically which allows you to better pinpoint the issue and begin troubleshooting.
Utilizing a program like SolarWinds Server & Application Monitor (SAM) you can keep track of Windows Server metrics alongside a array of different application and server metrics. SAM offers more than 250 standard templates to monitor servers and applications that you can use to create your own or modify according to the needs.
With SAM you will learn about the most important performance indicators for servers in relation to response times as well as packet loss memory capacity and capacity of disks as well as hardware failures and much more.
For example an example, the SolarWinds templates to Windows Server would include a variety of monitors for components, which include:
- Services such as Distributed Transfer Coordinator Security Accounts Manager Remote Registry, Server
- Metrics such as memory pages, page file usage as well as % processor time and the length of the queue on disks
Use Tools
As I said earlier the use of tools to monitor the performance of your computers that run Windows Server is important for being able to identify and fix issues. There are many different tools that can be used to monitor server performance. Some of them only look at the key metrics but don’t allow the capacity planning or historical trends while some are more thorough and provide more extensive monitoring of applications and networks along with server’s performance.
My preferred Windows Server Performance Monitor tool that I mentioned previously is SolarWinds Server & Application Monitor as it comes with high-quality tools for Windows Server monitoring specifically, as well as a variety of other application and server monitoring tools.
The first is that SAM has built-in charting of forecasts to help plan capacity making it possible to see the moment when your server’s resources be at a certain point or start to encounter problems. This is a crucial element of managing the Windows Server Performance Monitor because capacity planning and alerting could aid in preventing and avoiding issues before they happen.
Furthermore, you’ll be able to also monitor the CPU’s utilization, memory issues and disk space issues using SAM to monitor the components of your system that are struggling.
SAM can also be useful to baseline, since it contains historical data specifically to establish what normal consumption of resources looks like. In addition, for Windows Server monitoring, you will also be able to get data on loading balancing and FTP updating, remote Desktop functions processing time, length of the disk queue and page file usage to get a better knowledge about the performance of your Windows Server performance in a more organized manner.
With its real-time troubleshooting tools SAM can also help you detect if any irregular procedures as well as performance concerns have arose. This is a crucial component of security surveillance as previously mentioned. I appreciate the way SAM helps in both aspects of the monitoring process.
In addition, SAM includes IT asset inventory scanning and discovery tools. This will let you know all you need to know regarding your hard drives as well as drivers, firmware processors, memory, networks interfaces, updates software, and all the other information that you may need to know about the happenings within the IT environment.
As I’ve mentioned before the importance of setting baselines that look at the entire system is vital and using SAM’s monitoring and inventory scanning tools will give you a more of a complete picture of where problems with performance might be emanating from. You can test SAM at no cost up until 30 days.
Set Up Alerts and Reports
Make sure that you have set up your system to generate automatic alerts and reports so that you can have the information needed available to you in both historical and real-time views in the event of performance problems. Alerts regarding the above-mentioned parameters will ensure that you aren’t missing a possible problem by alerting you when an indicator is above the specified threshold.
Reports can aid in creating an inventory of past data that lets you check back in the past to determine what issues are appearing frequently. Additionally, periodic reports will allow you to review the past and identify the security problems or attempts to invade that you not noticed the previous time.
If you can tailor your reports to only show the information that is relevant to your business or subject it will also help you reduce time by not revealing details that aren’t relevant to you.
Getting Started With Windows Server Monitoring

When you’re beginning to get started on the initial steps of your Windows Server setup, you’ll be looking for a program which can automate as much Windows Server performance monitoring as possible, as manual monitoring isn’t feasible for most companies. My top recommendation for Windows Server performance monitors includes the SolarWinds Server and Application Monitor.
With SAM you’ll get the tools that you require to use the best methods for monitoring performance that go beyond what you can do using Microsoft’s inbuilt Windows Server tool.
Server Monitor
Monitoring Servers is the procedure of monitoring the server’s system resources such as CPU Usage, Memory Consumption I/O, Network Process, Disk Usage and more. Server monitoring also aids in capacity planning through understanding the use of resources on the server. Server monitor software aids in the automation of monitoring servers. Monitoring server performance helps in identifying performance related issues such as resource usage as well as app downtime and response time.
Why is it necessary to track the performance of your server?
- To track the availability of servers and to prevent loss of data.
- Monitor the server’s responsiveness.
- To find out the server’s capacity to determine the user load, speed and capacity of the server.
- To prevent and detect issues that could impact the server’s performance.
Server performance monitoring is part of ManageEngine OpManager
OpManager offers support for multiple vendors that allows you to Monitor Server and all their important applications, as well as their processes and services. It continuously monitors servers using SNMP as well as WMI protocol, to ensure they’re operating at their peak performance 24/7.
It archives all data to track performance over time and for troubleshooting, thereby getting rid of the need for a separate tools to monitor servers. Gain in-depth insight in real-time and track server performance efficiently with OpManager.
Gathering Windows Server Performance Monitor Information

It is possible to use Microsoft’s Windows Server Performance Monitor to collect data on system performance that will assist Coveo support team in resolving Coveo server issues with performance.
The following steps will show you how to set up the Performance Monitor to report processor disk, memory, and processor performance information, respectively , for Windows Server 2008.
The ability to enable a performance counter is available for processors, disks, as well as memory objects (Windows Server 2008)
- With an administrator account Connect using an administrator account, connect to Coveo using an administrator account. Coveo server.
- To open the Windows taskbar, click Run. > Run.
- Within the Run box type perfmon and then click OK.
- In Performance Monitor:
- On the panel to the left side, expand Data Collector Sets.
- Right-click on User Defined, select New Data Collector Set in the context menu.
- In the Create New Data Collector Set wizard dialog box:
- Within the name box enter CoveoPerformances.
- Choose the option to manually create (Advanced).
- Click Next.
- The second a new Data Collector Set wizard dialog box:
- Select Create data logs.
- Choose the Performance counter check box.
- Click Next.
- The third New Data Collector Set wizard dialog box:
- Click Add.
- The dialog box that displays in the list of counters available Select the next counters that perform, then click Add for each one of them:
- Memory
- PhysicalDisk
- Processor
- Click OK.
- The dialog box that displays in the list of counters available Select the next counters that perform, then click Add for each one of them:
- Click Finish.
- Click Add.
- If you’re ready to begin collecting performance information, on the main panel to the right, click right-click on CoveoPerformances and select Start from the context menu.
- If you’re ready to stop collecting performance data, in the main panel to the right side, right-click CoveoPerformances and select Stop from the contextual menu.
- To look over the logged performance information, using Windows Explorer, locate and double-click on the .blg file that is listed in the column Output in the Performance Monitor.The Performance Monitor opens showing the information that was collected.
- Forward the .blg file to Contact for Coveo Support
Important KPIs and Server Monitoring Metrics
IT applications are vital for today’s digital economy and for the business to succeed, these applications must be highly available and performing well. Performance decreases could be due to many reasons. There could be issues at the code level or database speed issues, or restrictions on bandwidth for networks. The IT applications are run by servers. If the server isn’t configured properly or performing well the application, it will suffer too. It is therefore important to track your efficiency of each servers within the data centre.
 Historically the most significant factors that impact the performance of servers are the utilization of the server’s CPU as well as the memory capacity. If the CPU utilization for a particular server extremely used (close to 100 percent) as well as there’s a high usage of memory (so there’s very little free memory in the server) then the performance of the applications running on the server will suffer.
Historically the most significant factors that impact the performance of servers are the utilization of the server’s CPU as well as the memory capacity. If the CPU utilization for a particular server extremely used (close to 100 percent) as well as there’s a high usage of memory (so there’s very little free memory in the server) then the performance of the applications running on the server will suffer.
IT administrators must also be able determine which are the most efficient CPU and memory-consuming processes running on the server to ensure that they can fix and troubleshoot the issue with resource utilization swiftly.
 While Monitoring memory usage and CPU utilization are without doubt vital, but as the server operating systems have changed it is essential to keep track of other performance indicators for operating systems for servers that can indicate performance bottlenecks. This blog outlines 10 crucial performance indicators, other than CPU and memory usage that must be tracked in relation to server performance.
While Monitoring memory usage and CPU utilization are without doubt vital, but as the server operating systems have changed it is essential to keep track of other performance indicators for operating systems for servers that can indicate performance bottlenecks. This blog outlines 10 crucial performance indicators, other than CPU and memory usage that must be tracked in relation to server performance.
| 1 | Monitoring Server Uptime |
 Uptime can be defined as the length of time the system was operating and up. It can be tracked since the last time the system was booted. It is possible to monitor it throughout every polling cycle, too. Monitoring the uptime is vital due to:
Uptime can be defined as the length of time the system was operating and up. It can be tracked since the last time the system was booted. It is possible to monitor it throughout every polling cycle, too. Monitoring the uptime is vital due to:
- This metric could be a signal to you that the system is functional, but has been down and then rebooted in the past (e.g. You may have accidentally set the system to apply auto-apply OS updates and it might have restarted in middle of the day and thereby affecting users).
- A lot of organizations follow the practice of rebooting their systems regularly. By monitoring system performance administrators can be alerted if the system failed to reboot in the reboot cycle that was set up.
| 2 | Monitoring Disk Activity |
The disk subsystem in the server is just equally important as the memory and compute subsystems. Disk activity is the length of time a disk drives is processing requests. There are several important indicators of the disk subsystem that need to be observed:
- The busy-time of the disk is the amount of time the disk is operational. If this number is greater than 100%, you can expect the requests that connect to the disk to queue up. From a diagnostic perspective it is essential to determine if the disk is occupied because of write or read operations.
- IOPs I/O operations that are performed to the disk are reflected in the workload on the drive. Monitoring the load over time will help you to identify the times where the system is under high workload.
- Disk read/write time This is the amount of time required to read/write blocks off the disk. The less time, the higher the performance.
- The length of the queue on disk If the disk isn’t able to handle the volume of requests it receives and more requests are added in the queue. To get the best performance, the queue should not be longer than 100. This reduces the time taken by a request while it is waiting to be served to the minimal.
- split IOPs A split file is usually done to maximize the use of the disk space. This procedure often leads to the disk needing to invest longer and use more I/O resources to service requests. This is because the splitting of a file scatters it into blocks, requiring the disk to carry out multiple write and read operations to serve requests. This results in a significant increases the I/O activities of disks on a server, slowing critical processes. By monitoring the extent of split I/O on the disk, administrators can detect proactively a situation that a disk is extremely divided.
While It is essential to keep track of the way the disk subsystem is functioning, to help diagnose other issues it is crucial to keep track of the activity of the disk at the level of the file. In particular, to identify which files are experiencing the most I/O activity. Monitoring tools like eG Enterprise, can identify and report on file-level I/O activity, which can impact the performance of an application.
Controlling the speed of performance for the disk subsystem can be very important in cases of workloads which are heavy on I/O. For instance, databases as well as file servers make extensive utilization of the disk subsystem; consequently, it is vital to examine disk subsystems’ performance metrics carefully for these servers.
| 3 | Monitoring Page File Usage |
The pager file in an OS increases its memory capacity. The data that is not utilized or recently accessed is kept inside the paging files. In addition, operations that are beyond the memory limit that are available to OS OS are automatically transferred to the paging folder to be archived.
The ideal paging file dimension should correspond to 1.5 times that of physical memory at minimum and as high as four times physical memory maximum to ensure stability of the system.
It is crucial to keep track of the usage of the paging file by the OS. If the utilization of the paging file is near 100%, this means that the paging file on the system isn’t big.
 When the use of the paging file is at or above 90 The system and the applications are unable to function correctly and will encounter slowdowns. The paging file you choose to use to be sufficient in size that, at any given moment that only 50 to 75% is being used at most , though lower numbers are more desirable.
When the use of the paging file is at or above 90 The system and the applications are unable to function correctly and will encounter slowdowns. The paging file you choose to use to be sufficient in size that, at any given moment that only 50 to 75% is being used at most , though lower numbers are more desirable.
| 4 | Monitoring Context Switches |
A context switch happens by switching the processor’s processor from one thread or process to another. Context switching is usually computationally demanding. Context switching can consume significant CPU resources and could be among the most costly operations of an OS. Thus, servers need to be set up and managed in a way that avoids excessively switching contexts in the maximum extent that is possible.
The high amount of context switches may be the result of a number of processes that are running at a high speed as well as a few idle ones. If the CPU utilization is low and the number of context switches is excessive, you’ll be required to pinpoint and eliminate the program responsible for the switches. Most likely, the increase in the rate of switching contexts could be due to an application-related bug.
The following figure shows servers’ context switches that was tracked over the course of the course of a week. In this instance an application update occurred just at the time the rate of context switching on the server was increased nearly four-fold.
If this type of change were to occur on all Virtual Machines (VMs) which are running on hypervisors, the effect on the hypervisor’s utilization of compute could be significant. A server monitoring tool should be able to detect and alert administrators to these abnormalities. In this case the higher context switching rate was caused by an issue with the application which was updated.
A sudden increase in the number of the number of switches in a server’s context is a sign of a problem.
| 5 | Monitoring Time Synchronization |
 When several systems connected to the same network connect to files or communicate with one another, various tasks they carry out could be time-bound, or need to be completed in a sequential manner. The system clocks are frequently used to accomplish this, but when the clocks of the system on different systems don’t have the exact time, the consequences could be disastrous.
When several systems connected to the same network connect to files or communicate with one another, various tasks they carry out could be time-bound, or need to be completed in a sequential manner. The system clocks are frequently used to accomplish this, but when the clocks of the system on different systems don’t have the exact time, the consequences could be disastrous.
For instance, if two machines share files on an internet connection the clocks of these machines should be synced to identify when the files were altered. Inaccurate clocks can cause conflicting versions or lead to data to be lost. In the case of a Microsoft Windows domain, timestamps are used to resolve Active Directory replication conflicts. Kerberos authentication also is dependent on time stamps.
They are used to guard against replay attacks, where the authenticating packet gets intercepted by the network, only to be resent later in order to authenticate on the initial sender’s behalf. When an Windows server receives an authentication request from Kerberos it compares the timestamp of the request to the local time.
If the gap between the timingstamp and local time is too large the authentication request will be denied and the Kerberos authentication is not successful. In order for Kerberos to function correctly it is essential that the clocks of all systems within the Windows domain need to be properly synchronized.
 Monitoring tools should examine the offsets of clocks on an individual system in relation to an appropriate benchmark clock e.g. or an Active Directory server’s clock. While minor offsets are generally acceptable, if there’s significant offsets between any clock of the system as well as the clock referenced administrators should be informed of such deviations.
Monitoring tools should examine the offsets of clocks on an individual system in relation to an appropriate benchmark clock e.g. or an Active Directory server’s clock. While minor offsets are generally acceptable, if there’s significant offsets between any clock of the system as well as the clock referenced administrators should be informed of such deviations.
| 6 | Monitoring Usage of Handles |
We often think of CPU, memory and the disks as primary servers’ resources. There are different kinds of resources, including network sockets, file descriptors processing jobs, processes, etc. These resources are all limitless as there is an enumeration of files that are open at any one time on servers. The handle can be utilized to denote the resource that applications refer to.
Applications are required to ask for and receive resources for use, before returning them to the OS. A handle leak happens when an application fails to return the handle following use back to OS. The most common cause for the leak of a handle is a programming error, such as the developer opens the file object, but then forgetting to close the file.
Handle leaks could be caused by exceptions. Blocks that are exceptions may not include the same cleanup procedures that the code block contains.
Repeated or frequent leaks of handles for a prolonged period suggest that some handles could be identified as in-use and therefore unavailable. This can cause server performance to suffer or lead to it be unable to function properly.
 To keep from such disasters administrators should monitor the usage of handles in time. If the number of open handles is increasing consistently this could indicate leaks in handle. Administrators might want to look further and identify processes that have the highest number of handles open. By removing these processes or patching the programs that started these processes could help to lessen the leak.
To keep from such disasters administrators should monitor the usage of handles in time. If the number of open handles is increasing consistently this could indicate leaks in handle. Administrators might want to look further and identify processes that have the highest number of handles open. By removing these processes or patching the programs that started these processes could help to lessen the leak.
| 7 | Monitoring Process Activity |
The processes running on servers require monitoring. A silent killer can be a the leakage or leaking of information. For instance, an application may start creating new processes frequently without stopping the ones that were previously running. This can lead to a huge number of running processes in the background on the server. Multi-tasking over a multitude of processes could significantly reduce the efficiency that the server. This is why it is essential to keep track of the number of processes running on servers.
The usage of resources by each process must be monitored , too. This is often helpful in diagnosing If servers are running at a high rate of memory usage, what are the processes that caused this memory leak?
| 8 | Monitoring Network Traffic |
 Server performance could be affected by malfunctioning network cards. Check the number of errors that are detected on the network interface card on the server in order to identify ones with the most packet drop.
Server performance could be affected by malfunctioning network cards. Check the number of errors that are detected on the network interface card on the server in order to identify ones with the most packet drop.
In the same way it is crucial to keep track of the bandwidth used for each interface. If bandwidth utilization is near the speed at which the network interface can operate at its maximum network interface, it may signal a bottleneck that impacts performance.
Compare the bandwidth for each interface, and make sure that all network traffic is directed through the primary interface that you are planning to utilize. The excessive traffic on an alternate interface could be a sign of a routing table problem on the server that needs to be fixed.
| 9 | Monitoring TCP Activity |
 Most commonly used enterprise applications are oriented towards connection, as is TCP is the protocol for transport that they utilize. This means that the speed of operation for the TCP layer could affect the application’s performance.
Most commonly used enterprise applications are oriented towards connection, as is TCP is the protocol for transport that they utilize. This means that the speed of operation for the TCP layer could affect the application’s performance.
HTTP, SMTP, SQL and many other kinds of connections rely on TCP beneath. Thus when TCP performance decreases as does the performance of the programs which use them.
To monitor TCP performance it is essential to track the following indicators:
- The amount of connections between and to the server. It is not just a way to gauge the load on the server, but it could be an indication of instances when the server is being attacked.
- Drops in connection in the servers must be monitored. The frequency of connection drops can be reason to be concerned.
- Most likely, the most significant performance metric to be tracking in TCP can be the proportion of retransmissions. To ensure an optimal TCP performances, retransmissions must be kept to a minimum. A number of 5 percent is acceptable but anything higher than 10% could significantly affect performance and latency for the application. Retransmissions happen when a segment is transmitted by the server but acknowledgement isn’t accepted by the server when it is received from the user. In this case the server must transmit the segment after a timeout timer.
Retransmissions are transmitted over an TCP connection
The most common reasons for retransmissions are the presence of network congestion, where packets are lost (either the TCP segment goes missing while traveling to its destination, or the ACK gets lost along its return journey returning to sender) or strict router QoS rules that provide preferential treatment to specific protocols, as well as TCP segments that are in a different order at their destination, often due to the fact that the order of segments were misplaced when they traveled from the sender to destination.
Retransmissions aren’t just dangerous because they require timeouts and Retransmission. TCP utilizes a windowing method. The window indicates the number of segments that are not yet acknowledged. In regular transmissions, the size of the window doubles when the sender receives acknowledgements. However, when a retransmission occurs then the window size shrinks by half. Retransmissions repeatedly can cause an extreme reduction in throughput.
Compare the retransmissions between various servers. If multiple servers experience significant retransmissions, it could indicate that the problem is network-related. However, the issue may be unique to the server’s setup, e.g., a malfunctioning NIC card.
| 10 | Monitoring OS Log Files |
It isn’t possible to fully monitor every part of the operating system for servers. The details of any issues encountered or crashes observed, as well as other kinds of anomalies are recorded by the Operating systems’ logs.
Microsoft Windows has System, Security as well as Application Log files. Events of various types and coming from various sources are recorded here. The events are classified as explicit, informative, warning or even crucial.
On Unix servers System log as well as cron logs files located in the /var/log directory offer insight into the abnormalities that occur within the servers. Syslog is a different type of recording operating system irregularities.
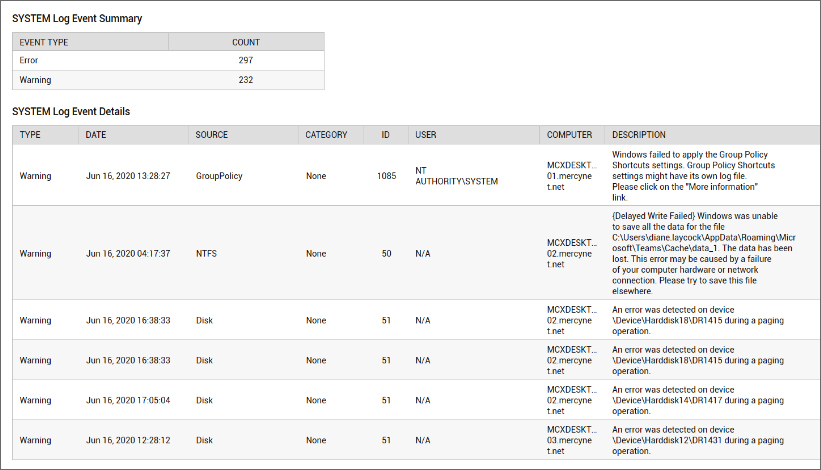
It does not feasible administrators to analyze manually the logs of 100s of servers in order to discover problems. Monitoring, analysis and alerts of log events could uncover issues with the server to the light. Some examples of issues that can be discovered through log monitoring are:
- Multiple crashes of an application or library
- Failure to sign in to a server
- Disk read problems are due to the disk drive being damaged
- Inability to follow the group’s policies
- DNS name resolution failures
- Issues with printing
- Security-related mistakes
- Time problems with synchronization
- Patch update fails to update
Conclusion
In the end, it must be apparent from the above review that monitoring the performance of servers should be more than memory, CPU, or use of disk space. The fundamental principles that are discussed in this blog can be applied to all server operating systems.
Incorporating a complete system for monitoring and managing servers is the most important step to ensure your IT infrastructure as well as the applications that it runs functioning properly.





